- Article
How Does Multilingual Data Annotation Improve Machine Learning
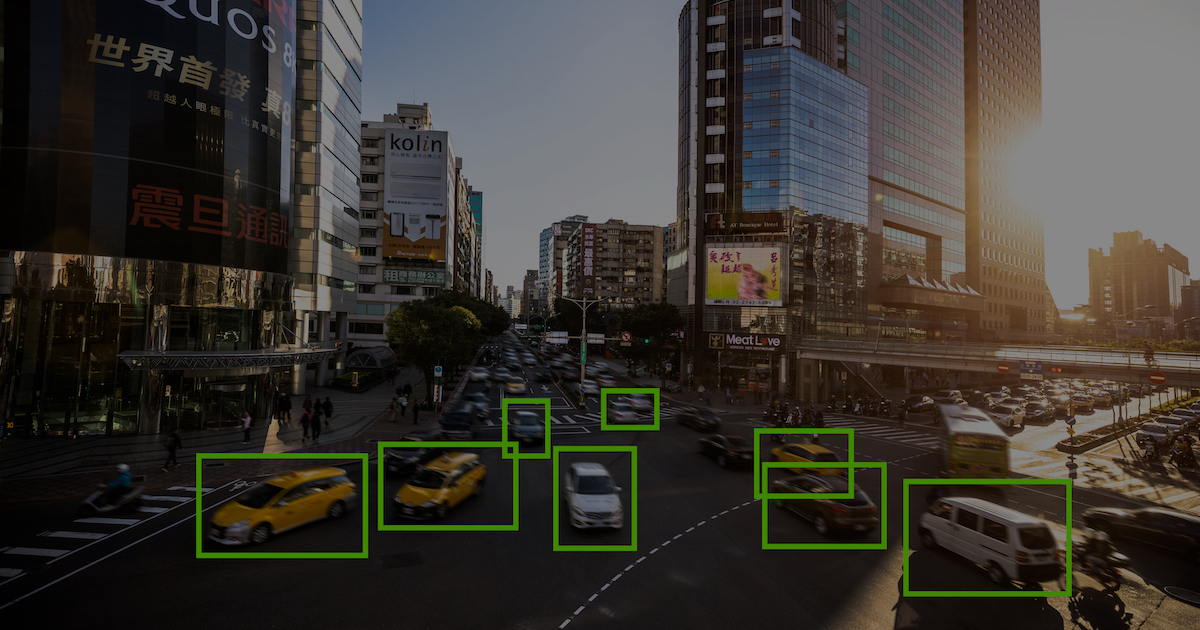
Machine learning is all around us. From voice search to music recommendations, you likely enjoy the benefits in everyday life. However, for this to happen there needs to be machine learning model training: a continuous process where the machine is fed algorithms to automatically learn patterns based on the data received. This process allows a machine learning model to learn on its own. And that’s where data annotation comes in.
Simply put, data annotation is a method of labeling any type of data including text, audio, images, and videos. Any data you feed the model’s algorithm needs a data tag—or label—to classify what it is. For example, say you want the algorithm of a smart car to identify pedestrians. That would require tagging numerous images of people to train it to see and avoid pedestrians while it’s operating.
Now, given our increasingly interconnected world, it makes sense to train machine learning models in multiple languages so that they work anywhere. This is known as multilingual data annotation and requires data translation to create tags in each language. But before we dive into the benefits, let’s take a deeper look at machine learning.
How machine learning works
Below is a brief overview of how data scientists train a machine learning model to learn on its own.
First, the data scientist will select and prepare a data training set. (Here’s where all that data tagging pays off.) The training set represents the type of data it needs to learn how to solve a particular problem.
Next, the data scientist will choose the right type of algorithm to run the training data. Algorithms that run labeled data include regression algorithms, decision trees, and instance-based algorithms.
Then it’s time to start training the algorithm to create a model. The data scientist will run variables through it and compare its output with the results it should have produced. Over time, the algorithm will become more and more accurate.
Finally, the data scientist will try using the model with a new data set to see how it performs. At this point, the model should be able to identify new, unlabeled data based on the patterns it learned from the annotated data.
Types of annotated data
As you can see, data annotation is an essential first step in the machine learning process. The type of data tag you use will depend on the goal of the machine learning model. Below are just a few:
Image annotation and video annotation: This type of annotation trains machine learning models to understand content in images and videos. Using an image or video annotation tool, you can create borders around objects you want it to recognize. Going back to the smart car example, you can use photo annotation to draw boxes around pedestrians, vehicles, and any other objects you want it to avoid.
[form_newsletter]
You can also use image tagging to train algorithms to block sensitive content or identify product listings on ecommerce sites.
Semantic annotation: Semantic annotation lets you label concepts within text such as people, objects, or company names. You can also use it to categorize new concepts, improve search relevance, and train chatbots.
Entity annotation: Entity annotation lets you label unstructured sentences with information to help a machine learning tool read them.
How much training data is enough?
Okay, so you’re probably wondering how much data tagging you’ll need to do before a machine learning model starts running optimally. The answer is: it depends. It could need hundreds, thousands, or even millions of data points. Factors that influence how much data training it needs include the complexity of the model, training method, labeling needs, and your tolerance for errors.
Since it’s nearly impossible to know how much data you need beforehand, you’re likely better off starting with the data set you have. Once you see the model’s output, you can keep adding more clean data until it achieves the desired outcome.
The benefits of multilingual data annotation
Given the amount of work it takes to tag data in one language, it may seem overwhelming to even consider doing it in another. However, data translation does help you create better, more accessible machine learning models. It’s especially helpful for creating something in a less common language. For example, you could translate sample responses for a chatbot from English to Dutch to better assist people in Dutch-speaking countries.
Just keep in mind that data sets require larger and more specific translation rules than typical translations. You’ll want to work with a translation company that has experience with these types of projects. That’s because a high-quality translation is key when it comes to creating a system that recognizes words, images, text, and commands in multiple languages.
Data translation use cases
Now that you know more about data translation, let’s take a look at a couple of use cases.
Voice search
As of 2020, voice search makes up about 50% of all internet search queries. People also tend to search in their native tongue, which means search engines not only need to read multiple languages but understand the spoken word as well. And that requires voice search translation.
Here’s how it works. A translator receives text files directly from someone’s speech. Since people speak differently than they write, the translator needs to think like an interpreter and only translate words that have meaning. (That means leaving out words like uh and um a searcher may use while thinking of how to phrase the query.)
Then the translator needs to build up subject matter vocabulary and phrases to help the algorithm better understand which responses provide the best answers.
Finally, the translator records the audio of their translation to feed the algorithm along with a text version.
In order to train it on how people sound, speakers of different ages, genders, and with different accents record audio examples.
Social media machine translation
If you have Facebook friends who post updates in another language, you’ve probably noticed that it automatically translates those posts. That’s machine translation in action.
Because people tend to use slang and abbreviations when they post, it’s up to the algorithm to make the translation sound natural. French teens, for example, use ‘uau’ as an equivalent of ‘wow’ on social media. Facebook’s algorithm was able to learn this and can now produce a translation that maintains teenage slang.
Through the use of convolutional neural networks (CNN), Facebook’s algorithm can mimic the way a human would translate a sentence. Instead of reading it once and translating it, CNN reviews the sentence multiple times to check the meaning, just as a human translator would. This allows for a stronger, more natural-sounding translation.
The Role of Human Translators
While it may seem as though machine learning models can do it all, human translators still play a vital role in multilingual data annotation. A combination of supervised data translation and quality assurance remains the best way to create clean multilingual data sets.
At Argos, we partner with qualified linguists to deliver multilingual data sets of text, voice, and image data that work for test sets and training sets. Using V_Data, our custom suite of data collection tools, we manage natural language processing (NLP) translation projects for all of the above.
Interested in learning more about how multilingual data annotation can improve your machine learning models? Get in touch for more information.